Classification of diabetes in people of Pima Indian heritage
|
Goal |
This dataset is originally from the National Institute of Diabetes and Digestive and Kidney Diseases. The objective of the dataset is to diagnostically predict whether or not a patient has diabetes, based on certain diagnostic measurements included in the dataset. Several constraints were placed on the selection of these instances from a larger database. In particular, all patients here are females at least 21 years old of Pima Indian heritage. |
|---|---|
|
Opportunities |
TODO |
|
Challenges |
Dealing with the class imbalance in the target. |
|
Value propositions |
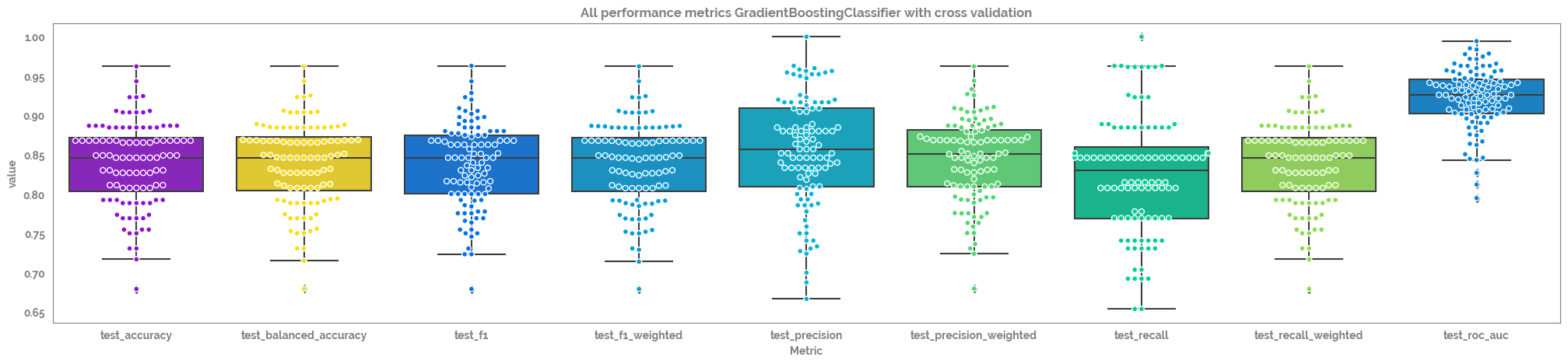
It is indeed possible to classify diabetes in the dataset to a high level of performance (median accuracy in cross-validation = 0.85). |
Approach
TODO
Outcome
TODO
References
- Friedman, J. H. (2001). Greedy function approximation: a gradient boosting machine. Annals of statistics, 1189-1232.
- Lundberg, S. M., & Lee, S. I. (2017). A unified approach to interpreting model predictions. Advances in neural information processing systems, 30.
- Smith, J.W., Everhart, J.E., Dickson, W.C., Knowler, W.C., & Johannes, R.S. (1988). Using the ADAP learning algorithm to forecast the onset of diabetes mellitus. In Proceedings of the Symposium on Computer Applications and Medical Care (pp. 261--265). IEEE Computer Society Press.
Appendix
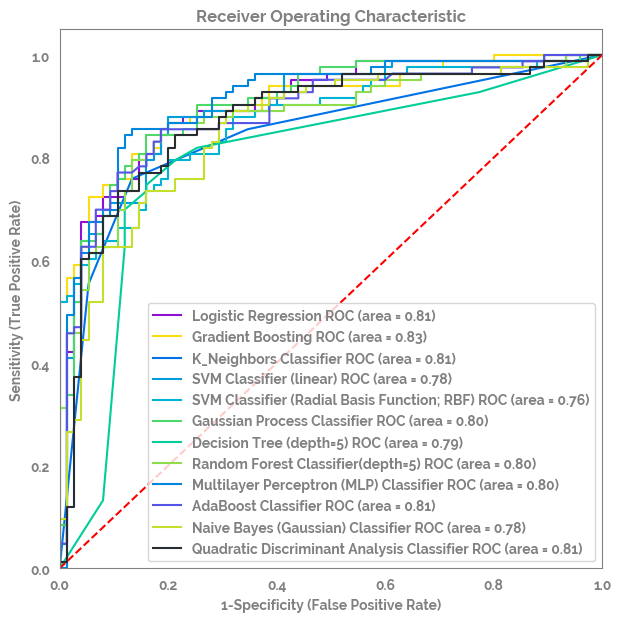
ROC AUC curves per a range of different models in
order to compare. Model list: Logistic Regression,
Gradient Boosting, K-neighbours,
Support Vector Machine, Gaussian Process, Decision
Tree, Random Forest, Multilayer Perceptron,
AdaBoost, Naive Bayes, Quadratic Discriminant
Analysis.
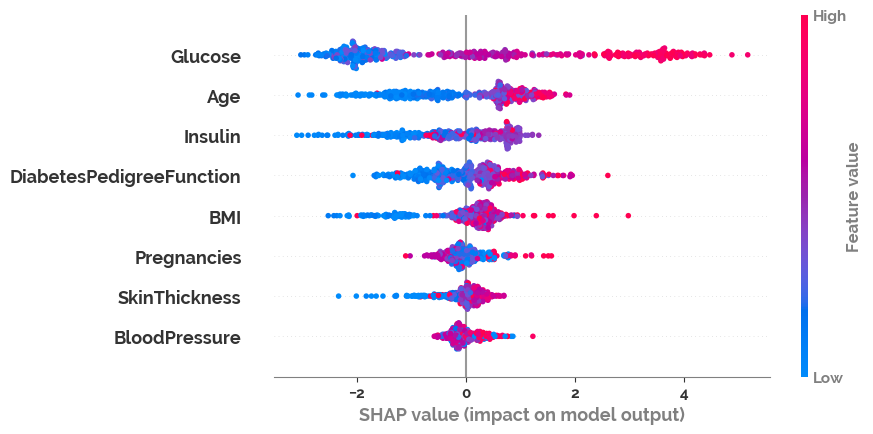
Feature importances in the target classification using
SHAP values. Here it can be seen that glucose amount
is the most important feature in classifying
diabetes, and blod pressure is the least importance. The cross validation metrics of the final model
(Gradient Boosting Classifier), with all of
these metrics the closer to 1, the better.Appendix 1: Model Comparison
Appendix 2: SHAP feature importance
Appendix 3: Cross validation metrics