Pricing Exploratory Data Analysis¶
Client request¶
Here is an excel file with 2 data sets. This is actual data.
The first data set is a standard correlation where the baseline and benchmark show a strong correlation according to my simple method The second data set is an example where the correlation is good, until it is not for a period of 12 months or so, before the lines come back together. This was caused by a disruption by a fire at one supplier after which capacity was limited and the link between market pricing and cost driver pricing was no longer relevant
Some notes The 2 data sets which I am running my analysis on are shaded in blue. I have added the formulas so you can see how they are calculated from the underlying data sets. Some of the data preparation (averaging, adjusting for lag, FX conversion) is not visible in this file but it is not so relevant for the statistics.
I would love to know if there is a better way to: - Understand or analyse the correlation between the 2 main lines - Understand the correlation between the base line and each of the individual cost drivers so that the cost drivers could be ranked in terms of relevance in some way
I am available to answer any questions about this data.
Read in necessary packages¶
[1]:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from jmspack.utils import (apply_scaling,
JmsColors)
from jmspack.ml_utils import plot_confusion_matrix, plot_learning_curve
from jmspack.frequentist_statistics import correlation_analysis
from dtw import *
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import KFold
from sklearn.metrics import mean_squared_error
import shap
Importing the dtw module. When using in academic works please cite:
T. Giorgino. Computing and Visualizing Dynamic Time Warping Alignments in R: The dtw Package.
J. Stat. Soft., doi:10.18637/jss.v031.i07.
/Users/james/miniconda3/envs/ds_env/lib/python3.9/site-packages/tqdm/auto.py:22: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
[2]:
shap.initjs()

Set plotting style¶
[3]:
if "jms_style_sheet" in plt.style.available:
plt.style.use("jms_style_sheet")
Read in data frames¶
Either the tab that has a clear correlation or not
[4]:
df_choice = "clear_result"
if df_choice == "clear_result":
df = (pd.read_excel("../data/Input for statistics v1.xlsx", sheet_name=0)
.assign(**{"Date": lambda x: pd.to_datetime(x["Date"]).dt.date})
.dropna()
.set_index("Date")
)
else:
df = (pd.read_excel("../data/Input for statistics v1.xlsx", sheet_name=1)
.assign(**{"Date": lambda x: pd.to_datetime(x["Date"]).dt.date})
.dropna()
.set_index("Date")
)
Show the head of the data frame¶
[5]:
df.head()
[5]:
| Baseline | Weighted benchmark | Benchmark index | EHA | Acrylic Acid | Styrene | |
|---|---|---|---|---|---|---|
| Date | ||||||
| 2018-01-01 | 1.026 | 0.98710 | 0.97850 | 0.945 | 1.111 | 0.929 |
| 2018-02-01 | 1.015 | 0.99460 | 0.99100 | 0.974 | 1.104 | 0.943 |
| 2018-03-01 | 1.006 | 0.97930 | 0.96550 | 0.952 | 1.004 | 0.953 |
| 2018-04-01 | 1.007 | 0.97780 | 0.96300 | 0.906 | 1.016 | 0.965 |
| 2018-05-01 | 1.012 | 0.97375 | 0.95625 | 0.900 | 1.049 | 0.938 |
Define the target and display simple summary statistics of the columns¶
[6]:
target = "Baseline"
[7]:
df.describe()
[7]:
| Baseline | Weighted benchmark | Benchmark index | EHA | Acrylic Acid | Styrene | |
|---|---|---|---|---|---|---|
| count | 56.000000 | 56.000000 | 56.000000 | 56.000000 | 56.000000 | 56.000000 |
| mean | 1.012518 | 0.999170 | 0.998616 | 1.139804 | 1.123946 | 0.865357 |
| std | 0.099634 | 0.113010 | 0.188350 | 0.264228 | 0.219361 | 0.183202 |
| min | 0.862000 | 0.825250 | 0.708750 | 0.846000 | 0.846000 | 0.499000 |
| 25% | 0.944750 | 0.937937 | 0.896562 | 0.935000 | 0.983750 | 0.770250 |
| 50% | 1.002500 | 0.980200 | 0.967000 | 1.030500 | 1.064000 | 0.933500 |
| 75% | 1.056250 | 1.055350 | 1.092250 | 1.360500 | 1.174500 | 1.003000 |
| max | 1.176000 | 1.208800 | 1.348000 | 1.664000 | 1.624000 | 1.193000 |
Plot the amount of rows in the target¶
[8]:
_ = plt.figure(figsize=(15, 4))
_ = sns.countplot(x=df[target])
_ = plt.xticks(rotation=90)
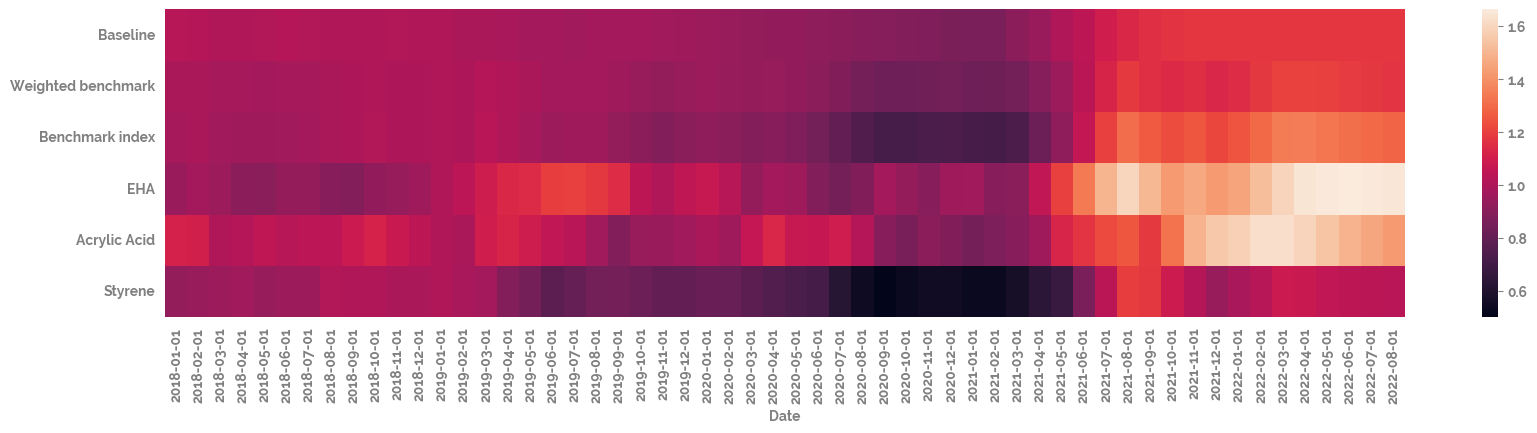
Plot the heatmaps of the raw and scaled data¶
[9]:
_ = plt.figure(figsize=(20, 4))
_ = sns.heatmap(df
# .drop(target, axis=1)
.T
)
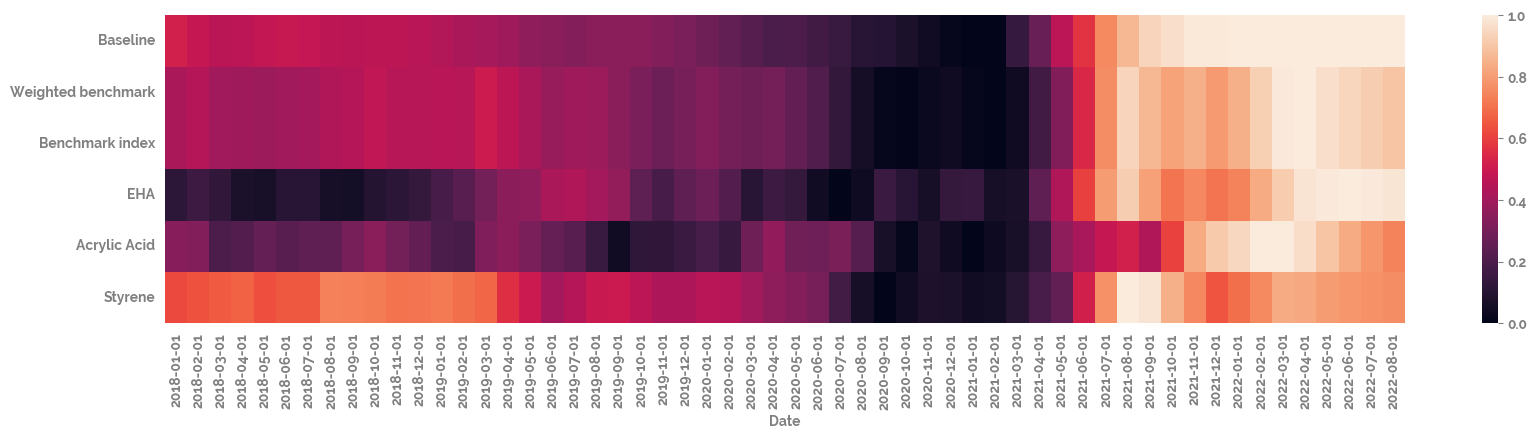
[10]:
_ = plt.figure(figsize=(20, 4))
_ = sns.heatmap(df
# .drop(target, axis=1)
.pipe(apply_scaling)
.T)
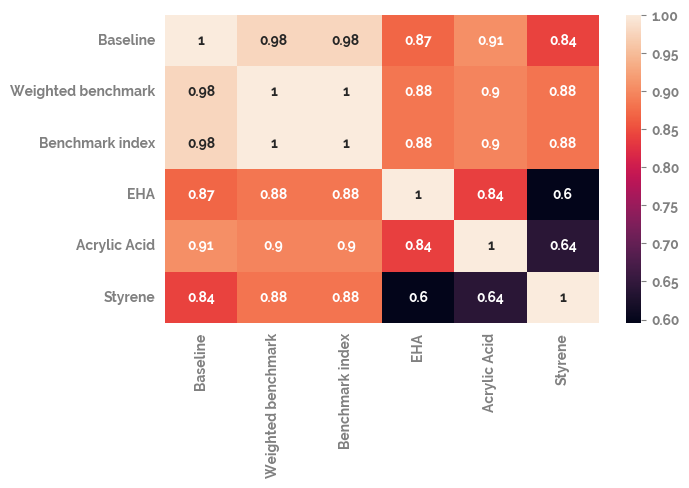
Plot the correlation of all of the different time series with each other¶
[11]:
_ = plt.figure(figsize=(7, 4))
_ = sns.heatmap(df.corr(), annot=True)
Plot the scatterplot of the variables to look for general (non time series related) trends¶
[12]:
_ = plt.figure(figsize=(20, 4))
_ = sns.stripplot(data=df
# .pipe(apply_scaling, "MinMax")
# .reset_index()
.melt(),
x = "variable",
y = "value",
)
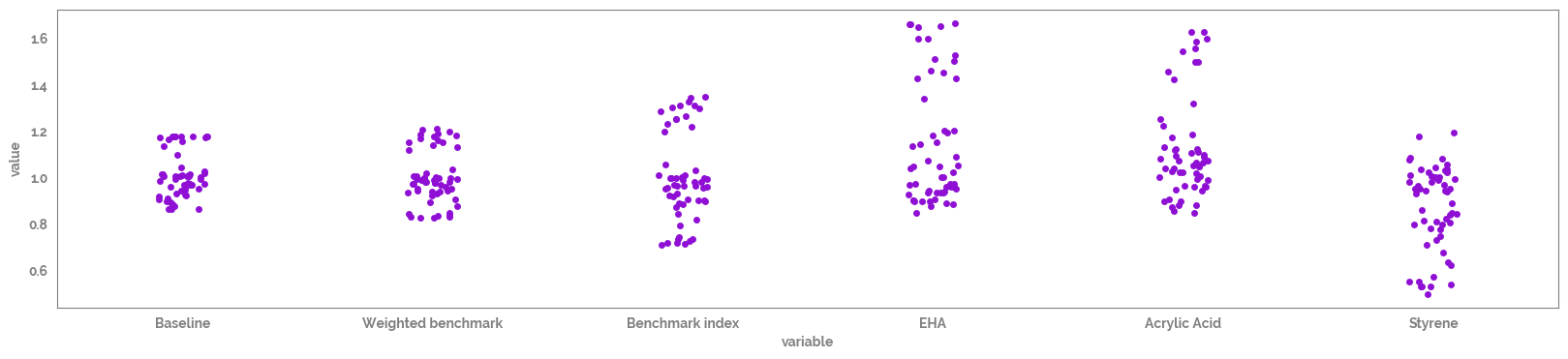
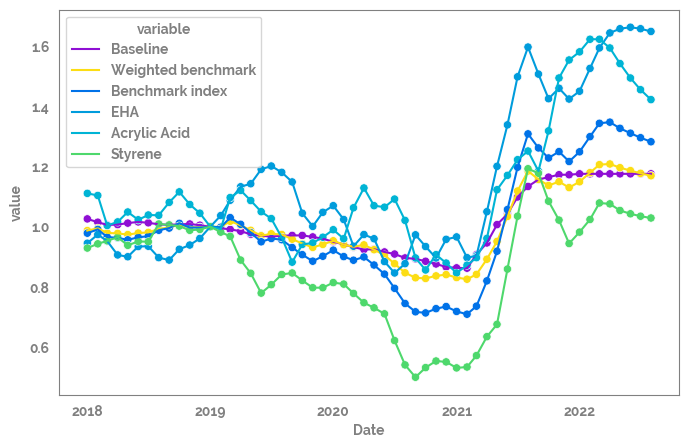
Plot all of the features over time¶
[13]:
_ = plt.figure(figsize=(8, 5))
_ = sns.lineplot(data=df
.reset_index()
.melt(id_vars="Date"),
x="Date",
y="value",
hue="variable"
)
_ = sns.scatterplot(data=df
.reset_index()
.melt(id_vars="Date"),
x="Date",
y="value",
hue="variable",
legend=False
)
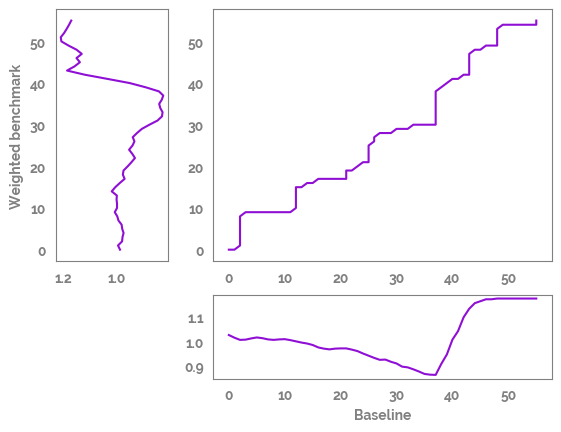
Threeway plot¶
[14]:
feature_1 = "Baseline"
feature_2 = "Weighted benchmark"
# feature_2 = "Chlorine"
query = df[feature_1].values
template = df[feature_2].values
## Find the best match with the canonical recursion formula
alignment = dtw(query, template, keep_internals=True)
## Display the warping curve, i.e. the alignment curve
_ = alignment.plot(type="threeway", xlab=feature_1,
ylab=feature_2)
Twoway plot¶
[15]:
_ = alignment.plot(type="twoway")
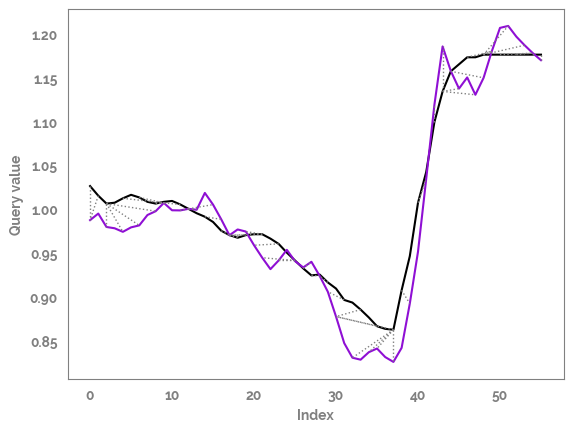
Twoway plot with rabiner Juang Step Pattern to align the time series¶
[16]:
## Align and plot with the Rabiner-Juang type VI-c unsmoothed recursion
_ = dtw(query, template, keep_internals=True,
step_pattern=rabinerJuangStepPattern(6, "c"))\
.plot(type="twoway",offset=0)
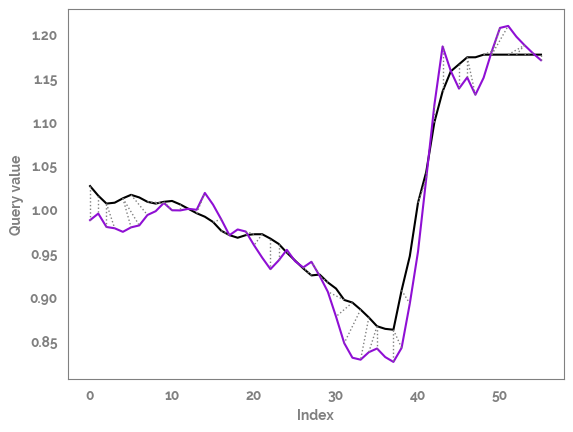
Threeway plot with cumulative cost density with the warping path overimposed¶
[17]:
_ = alignment.plot(type="density", xlab=feature_1,
ylab=feature_2)
[18]:
# _ = sns.heatmap(alignment.directionMatrix[1:, 1:])
[19]:
# _ = sns.heatmap(alignment.localCostMatrix)
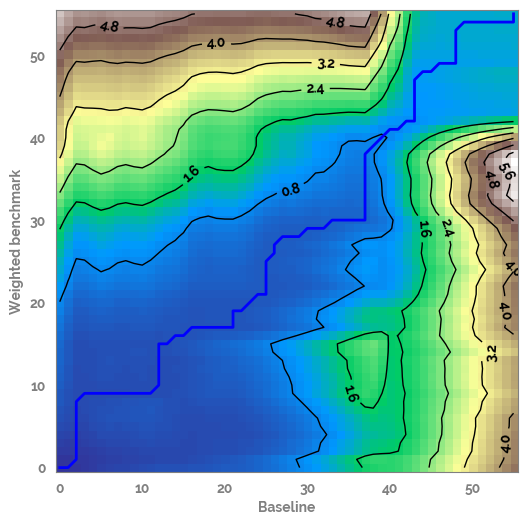
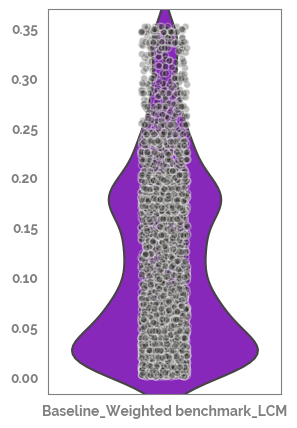
Plot the descriptive statistics of the localCostMatrix to allow comparison of alignments¶
[20]:
LCM_df = pd.DataFrame(alignment.localCostMatrix.reshape(-1,1), columns=[f"{feature_1}_{feature_2}_LCM"])
_ = plt.figure(figsize=(3,5))
_ = sns.violinplot(data=LCM_df)
_ = sns.stripplot(data=LCM_df, edgecolor="white", linewidth=1, alpha=0.3, color=JmsColors.YELLOW)
Setting a gradient palette using color= is deprecated and will be removed in version 0.13. Set `palette='dark:#fcdd14'` for same effect.
Show the descriptive statistics of the localCostMatrix to allow comparison of alignments¶
[21]:
LCM_df.describe()
[21]:
| Baseline_Weighted benchmark_LCM | |
|---|---|
| count | 3136.000000 |
| mean | 0.118301 |
| std | 0.092079 |
| min | 0.000000 |
| 25% | 0.034038 |
| 50% | 0.101250 |
| 75% | 0.182950 |
| max | 0.350750 |
Show the minimum global distance computed, not normalized.¶
[22]:
alignment.distance
[22]:
1.1479
Show the distance computed, normalized for path length¶
[23]:
alignment.normalizedDistance
[23]:
0.010249107142857141
Run a regression¶
Split the data frame to predictors data frame and target series¶
[24]:
X = df.drop(target,axis=1)
y = df[target]
X.shape, y.shape
[24]:
((56, 5), (56,))
Define the model¶
[25]:
mod = RandomForestRegressor(random_state=42)
# mod = LinearRegression(fit_intercept=True)
Fit the model to the whole data set and “predict” the target (there is no train test or cross-validation here)¶
[26]:
_ = mod.fit(X, y)
y_pred = mod.predict(X)
df_test = pd.DataFrame({"y_pred": y_pred, target: y})
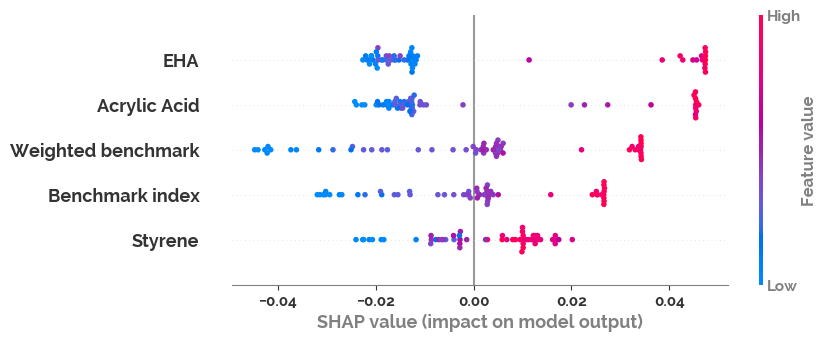
Use SHAP values to show feature importance in the model¶
[27]:
if mod.__class__.__name__ != "LinearRegression":
explainer = shap.Explainer(mod)
shap_values = explainer(X)
shap.plots.beeswarm(shap_values)
No data for colormapping provided via 'c'. Parameters 'vmin', 'vmax' will be ignored
Use gini importance values to show feature importance in the model¶
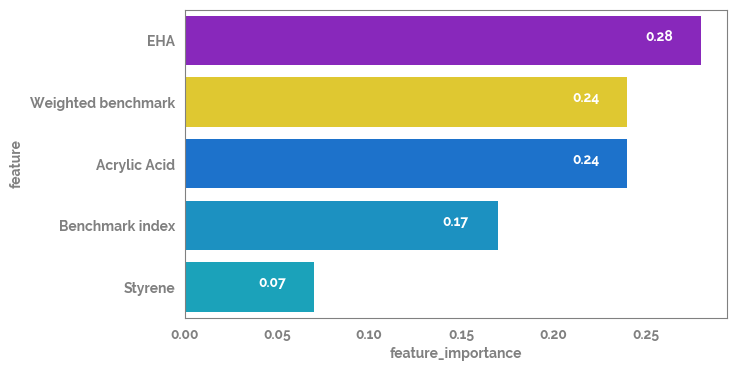
[28]:
feature_importance = pd.Series(dict(zip(X.columns, mod.feature_importances_.round(2))))
feature_importance_df = pd.DataFrame(feature_importance.sort_values(ascending=False)).reset_index().rename(columns={"index": "feature", 0: "feature_importance"})
_ = plt.figure(figsize=(7, 4))
_ = sns.barplot(data=feature_importance_df, x="feature_importance", y="feature")
for i in feature_importance_df.index:
_ = plt.text(x=feature_importance_df.loc[i, "feature_importance"]-0.03,
y=i,
s=feature_importance_df.loc[i, "feature_importance"],
color="white")
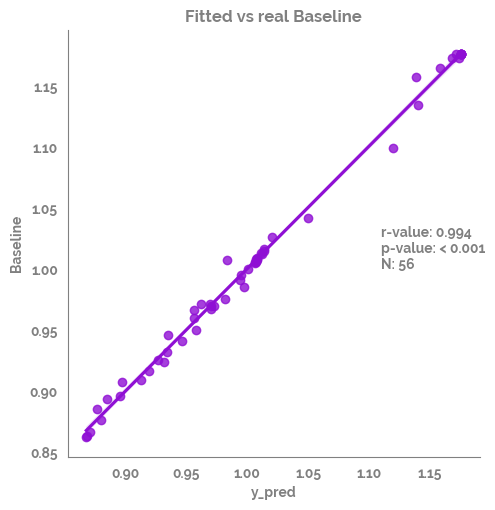
Show the correlation of the fitted vs the real target¶
[29]:
dict_results = correlation_analysis(data=df_test,
col_list=["y_pred"],
row_list=[target],
check_norm=True,
method = 'pearson',
dropna = 'pairwise')
cors_df=dict_results["summary"]
r_value = cors_df["r-value"].values[0].round(3)
p_value = cors_df["p-value"].values[0].round(3)
if p_value < 0.001:
p_value = "< 0.001"
n = cors_df["N"].values[0].round(3)
cors_df
The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
[29]:
| analysis | feature1 | feature2 | r-value | p-value | stat-sign | N | |
|---|---|---|---|---|---|---|---|
| 0 | Spearman Rank | y_pred | Baseline | 0.993958 | 1.658809e-53 | True | 56 |
Plot the linear relationship between the fitted vs the real target¶
[30]:
_ = sns.lmplot(data=df_test,
x="y_pred",
y=target)
_ = plt.annotate(text=f"r-value: {r_value}\np-value: {p_value}\nN: {n}", xy=(1.11,1))
_ = plt.title(f"Fitted vs real {target}")
[31]:
# import sklearn
# sorted(sklearn.metrics.SCORERS.keys())
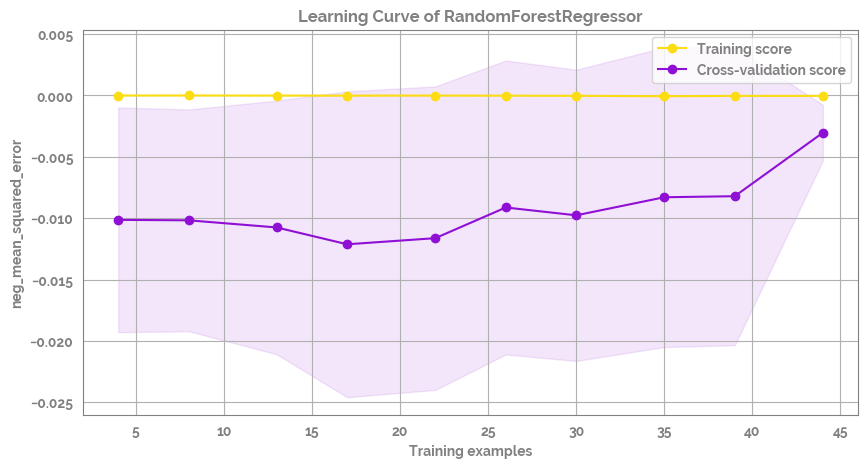
Plot the learning curve of the model - seems like it is not converging - likely it is overfitting (also sample size is small)¶
[32]:
fig = plot_learning_curve(estimator=mod,
title=f'Learning Curve of {mod.__class__.__name__}',
X=X,
y=y,
groups=None,
cross_color=JmsColors.PURPLE,
test_color=JmsColors.YELLOW,
scoring='neg_mean_squared_error', #'r2'
ylim=None,
cv=None,
n_jobs=10,
train_sizes=np.linspace(.1, 1.0, 10),
figsize=(10,5))
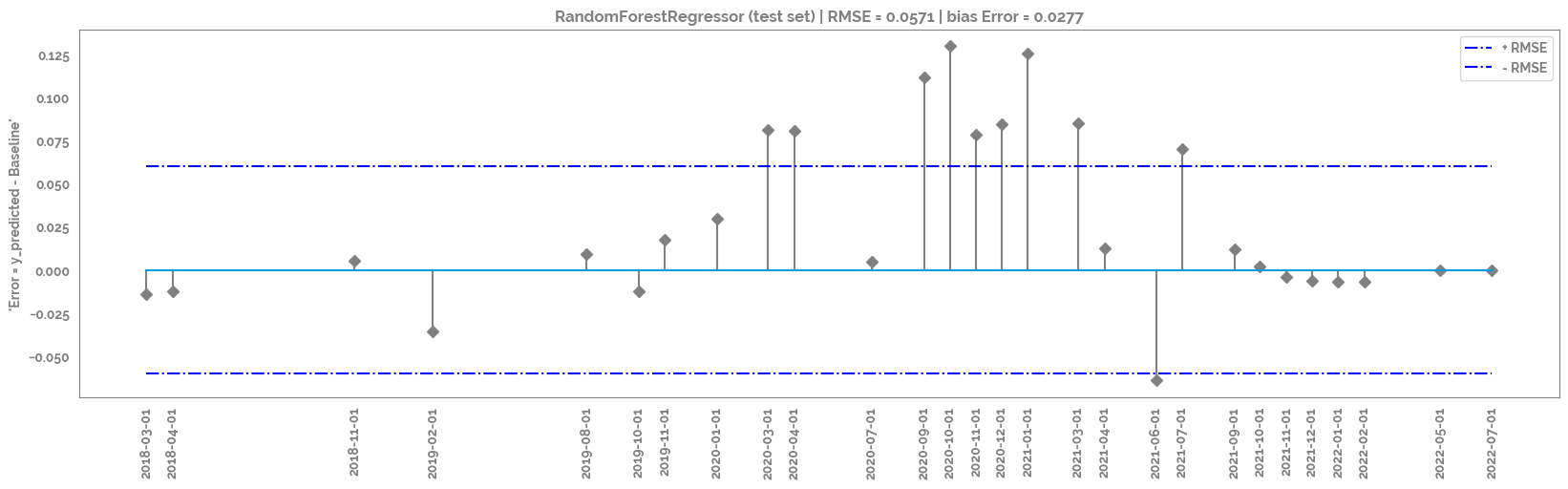
Run some cross validations (fit in train, predict in test)¶
Plot the difference between real and precited and the correlation between real and predicted
Redefine X to just use the top feature (in an attempt to stop overfitting)
[33]:
X = df[[feature_importance_df.loc[0, "feature"]]]
[34]:
kfold = KFold(n_splits=2, shuffle=True, random_state=1)
for train_ix, test_ix in kfold.split(X):
# select rows
train_X, test_X = X.iloc[train_ix, :], X.iloc[test_ix, :]
train_y, test_y = y.iloc[train_ix], y.iloc[test_ix]
_ = mod.fit(X = train_X,
y = train_y)
y_pred = mod.predict(test_X)
df_test = pd.DataFrame({"y_pred": y_pred, target: test_y})
user_ids_first = df_test.head(1).index.tolist()[0]
user_ids_last = df_test.tail(1).index.tolist()[0]
_ = plt.figure(figsize=(20,5))
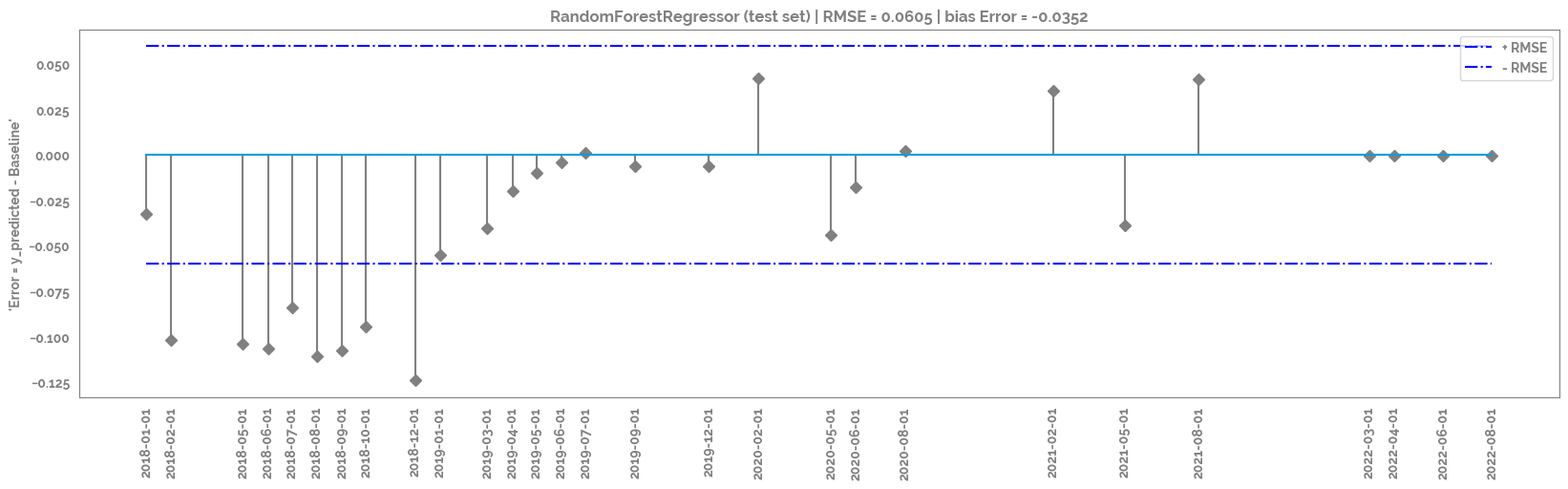
_ = plt.title(f"{mod.__class__.__name__} (test set) | RMSE = {round(np.sqrt(mean_squared_error(df_test['y_pred'], df_test[target])),4)} | bias Error = {round(np.mean(df_test['y_pred'] - df_test[target]), 4)}")
rmse_plot = plt.stem(df_test.index, df_test['y_pred'] - df_test[target], use_line_collection=True, linefmt='grey', markerfmt='D')
_ = plt.hlines(y=round(np.sqrt(mean_squared_error(df_test['y_pred'], df_test[target])),2), colors='b', linestyles='-.', label='+ RMSE',
xmin = user_ids_first,
xmax = user_ids_last
)
_ = plt.hlines(y=round(-np.sqrt(mean_squared_error(df_test['y_pred'], df_test[target])),2), colors='b', linestyles='-.', label='- RMSE',
xmin = user_ids_first,
xmax = user_ids_last
)
_ = plt.xticks(rotation=90, ticks=df_test.index)
_ = plt.ylabel(f"'Error = y_predicted - {target}'")
_ = plt.legend()
_ = plt.show()
dict_results = correlation_analysis(data=df_test,
col_list=["y_pred"],
row_list=[target],
check_norm=True,
method = 'pearson',
dropna = 'pairwise')
cors_df=dict_results["summary"]
r_value = cors_df["r-value"].values[0].round(3)
p_value = cors_df["p-value"].values[0].round(3)
if p_value < 0.001:
p_value = "< 0.001"
n = cors_df["N"].values[0].round(3)
display(cors_df)
_ = sns.lmplot(data=df_test,
x="y_pred",
y=target)
_ = plt.annotate(text=f"r-value: {r_value}\np-value: {p_value}\nN: {n}", xy=(1.11,1))
_ = plt.title(f"Fitted vs real {target}")
_ = plt.show()
The 'use_line_collection' parameter of stem() was deprecated in Matplotlib 3.6 and will be removed two minor releases later. If any parameter follows 'use_line_collection', they should be passed as keyword, not positionally.
The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
| analysis | feature1 | feature2 | r-value | p-value | stat-sign | N | |
|---|---|---|---|---|---|---|---|
| 0 | Spearman Rank | y_pred | Baseline | 0.698887 | 0.000035 | True | 28 |
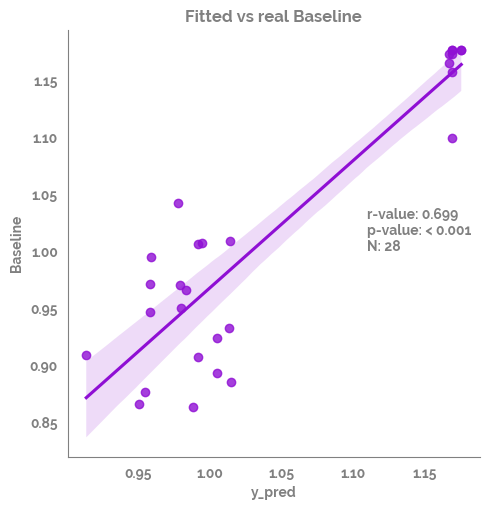
The 'use_line_collection' parameter of stem() was deprecated in Matplotlib 3.6 and will be removed two minor releases later. If any parameter follows 'use_line_collection', they should be passed as keyword, not positionally.
The frame.append method is deprecated and will be removed from pandas in a future version. Use pandas.concat instead.
| analysis | feature1 | feature2 | r-value | p-value | stat-sign | N | |
|---|---|---|---|---|---|---|---|
| 0 | Spearman Rank | y_pred | Baseline | 0.493671 | 0.007591 | True | 28 |
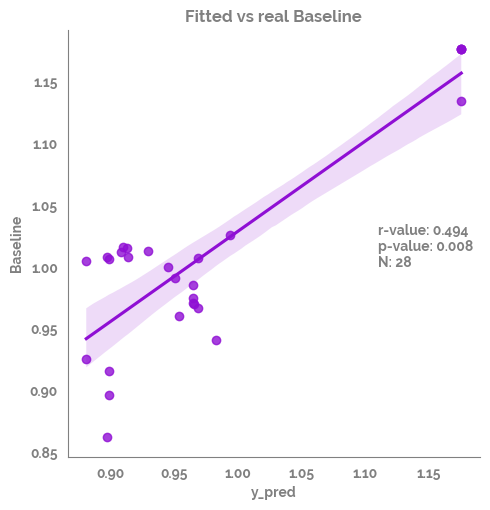
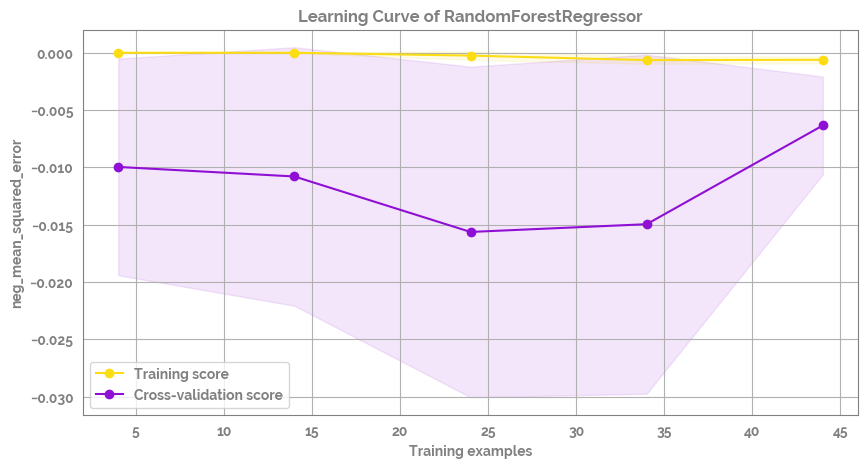
Plot the learning curve of the model - it is a bit better than before but still likely overfitting¶
[35]:
fig = plot_learning_curve(estimator=mod,
title=f'Learning Curve of {mod.__class__.__name__}',
X=X,
y=y,
groups=None,
cross_color=JmsColors.PURPLE,
test_color=JmsColors.YELLOW,
scoring='neg_mean_squared_error', #'r2'
ylim=None,
cv=None,
n_jobs=10,
train_sizes=np.linspace(.1, 1.0, 5),
figsize=(10,5))
[ ]: